

Like everyone else, I read Kieran Healy’s post on Paul Revere, the mostly highly connected person in Boston circa 1770. Healy, a sociologist at Duke, proved that Revere was an American “terrorist” kingpin by mapping his membership to several meetups, I mean, clubs. Healy worked his magic using a giant table or, technically, an adjacency matrix, connecting key figures in colonial Boston to the political meetings they belonged to. Data for building the tables came from David Hackett Fisher’s very fine Paul Revere’s Ride. It’s a book you should buy. I did, and it was the gateway drug to the extensive literature on the Revolution, but also to what’s known by social media theorists as a social attribute network or SAN.
There are a lot of papers on SANs, a subject at the busy intersection of sociology, computer science, graph theory, and machine learning. What is a SAN? It is essentially a graph that has been extended to include attributes or tag nodes shared by one or more of the social players (see graph below). As the human element, we’re the agents that form connections with others–that’s the social part. What about the attributes?
This is where the sociology research— going back to the 1940s — and the important “birds of a feather” principle comes into play. We form connections to others based on common interests or characteristics. Religion, ethnicity, education, income, age, and gender are markers or signals on which we base our bonding decisions. The more attributes we have in common with others the more likely we are to then have a connection or, in graph terms, form a link.
The fancy name for this is “homophily”, and there’s an excellent overview paper on the subject by Miller McPhereson et. al, which opens with one of highest wit-to-brevity ratio sentences of all time: “Similarity breeds connections.” By the way, I’ve also explored some of these ideas on another channel.
Computer scientists have been studying the whole area of linkability since the early days of the Internet, and the science of linking has itself spawned many, many papers. But two or three hops from any one of them will lead you to Jon Kleinberg.
A computer science professor at Cornell and known for developing, among many other accomplishments, a pre-Google page ranking algorithm HITS, Kleinberg has a great review of the various models, besides homophily, used for predicting linking: preferential (we link to the most popular folks), neighborliness (we’ll link to someone if we have lots of neighbors in common), convenience (we link to those who are “close” to in the social network), and more.
With social networks–Google+, IMDB, last.fm, Facebook — now providing real data, it was natural to test out different approaches to predicting links. It turns out that the homophily principle and some of its variations are quite powerful. In other words, the social network structure alone is not as predictive as social network with attributes.
The power of attributes to boost performance has been verified at least with Google+ and last.fm. Academic researchers took these data sets, created a SAN by using, in the case of Google+, information from profiles (occupation, education, places live), and for last.fm, the music sharing network, the user generated tags that categorize tracks. Their tests involved removing social links from the data sets, and then comparing how well SAN algorithms predict the missing links versus just using the social linking.
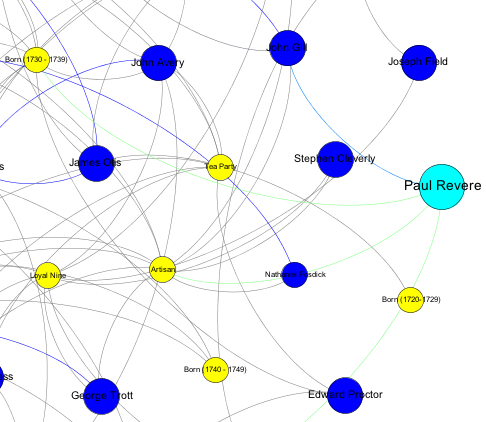
Back to Paul Revere and his SAN. In Healy’s post, he shows a very simple SAN with just a few attributes–a handful of Boston political groups. The social nodes are, or course, all the pre-Revolutionary figures swirling around Revere at the time. Can we extend Healy’s graph to include more attributes and perhaps predict likely links? Why, yes it’s possible.
So during the heat wave last month when I spent more than a few weekends within 6″ of a room air conditioner, I decided to build up a modest Revere SAN with attributes that included age (within a ten year range), church membership (churches were very important place in Boston to meet and share ideas), occupation, and education, as well as some political clubs.
Brief shout-out to Google Books for connecting me up with Esther Forbes’ Paul Revere and the World He Lived In, John Fiske’s Critical Period of American History, Ellen Chase’s Beginnings of the American Revolution, Ira Stoll’s Samuel Adams: A Life, David Conroy’s In Public Houses: Drink and the Revolution of Authority, and Caleb Snow’s A History of Boston, the Metropolis of Massachusetts.
Perhaps I went one or two nodes too far, but I managed to produce a SAN with 15 attributes and 21 social nodes, connected together with 87 edges. You can see a small part of it above–hat tip to Gelphi for helping me organize it. Based on my very modest research effort, it was easy enough to connect persons with attributes nodes based on the aforemetioned historical resources. To link directly, say, Thomas Crafts and Benjamin Edes, members of the mysterious Loyal Nine, I needed more evidence — a letter or diary entry indicating a relationship, which I did find. Lesson learned: historic research is time consuming.
What do you do with this information? You can borrow one of the link prediction algorithms used by researchers. The one that appealed to me is called Random Walk with Restart. It’s covered here in a paper by University of Illinois researcher Zhiujin Yin, who kicked off the whole SAN thing. Anyone familiar with Markov models or fans of Numb3rs will immediately grok it.
Essentially, your traverse the network like a maze, and throw the dice whenever you need to decide on which edge to choice to get you to next node. The dice probabilities are based on Yin’s formula– weighing attribute edges differently from social edges using a lambda or λ parameter. The Restart part of the algorithm says you can always return to the start of the maze— the social node you’re trying to learn more about–with some probability, controlled by the alpha or α parameter. The goal is to calculate a probability that you’ll land on a particular node– which is used as the likelihood of forming a link.
Yin gives some clues about how to set these parameters. You generally want to set the restart parameter on the high side, say .9, because you don’t want to give distant nodes too much weight–social closeness is something you want to try to preserve. And the attribute parameter depends, in a sense, on how much you trust the social links.
If you’ve gotten this far in the post, congrats. Here’s what I did. For the Random Walk algorithm, which I dutifully coded in PHP, I initially set α to .2 and λ to .6″, so that I could give more emphasis to non-local nodes and more weight to attribute nodes. This is mostly a reflection on my incomplete knowledge of the social links, and for kicks I just wanted to let this random walk wander a bit.
I started with that fellow Paul Revere as my source node. Let’s say the British snoopers knew him to be a Mason and an important member of the Saint Andrew’s Lodge, an artisan (silversmith), a pal of this publisher John Gill, and had some information on his birthdate. This information formed the basis of links to attribute node. Then I ran the model for 60 iterations, and checked to see that the probabilities were converging. So far so good.
Who would Revere form a link with then? Thomas Crafts, that’s who. He’s a good pick for a person of interest. You can learn more about him here. Crafts was part of the Loyal Nine, a member of the St. Andrews Lodge, an artisan (ship painter), and provided the Mohawk dress for the Tea Party, of which Revere played his part as one of the “Indians”.

And after I tweaked λ to .2 so that I would rely a little more on the social links, less on the attributes, who then made the list? That would be a Dr. Joseph Warren.
Interesting choice! The history books tell us Warren had a very close personal and business relationship with Revere, and was also the organizer behind the Midnight Ride. He was better educated (Harvard) and was in a professional class, but he was also a Mason and member of St. Andrews. Like Revere, he crossed attribute boundaries.
And this is all leading up to an important point that has been neglected in the analysis of the NSA’s metadata mining of phone records. Don’t for a nano-second think that that the NSA isn’t combining the metadata with other information. In the world of data protection regulation, phone numbers are considered personally identifiable information or PII–it’s sensitive information that links to a unique person or entity and is given special protections in financial and medical regulations. With the NSA’s phone data, their big data meisters can start pulling attribute data from other resources–the web especially–and then build an enormous SAN, which will be used to predict new links and relationships, and develop detailed profiles on behaviors.
The government has available much more than just phone records–they actually have a giant inference engine with a data center’s worth of personal data as input.